
Le web scraping est une technique largement utilisée pour extraire des informations à partir de sites web. Mais parfois, votre web scraper peut être limité par des restrictions d’accès. Une solution ? L’utilisation d’un proxy. Nous plongerons dans le vif du sujet en Python !
Qu’est-ce qu’un proxy ?
Un proxy agit comme un intermédiaire entre votre ordinateur et le site web auquel vous essayez d’accéder. Ce dernier peut aider à masquer votre adresse IP, augmenter la vitesse de vos requêtes et contourner certaines restrictions de localisation géographique.
Pourquoi utiliser un proxy pour le web scraping ?
Les avantages de l’utilisation des proxies
- Contourner les limitations d’accès : Certains sites web limitent le nombre de requêtes qu’une seule adresse IP peut faire dans un certain laps de temps. C’est une mesure de protection pour empêcher une surcharge de leur serveur. L’utilisation d’un proxy vous permet de contourner ces restrictions en distribuant vos requêtes à travers plusieurs adresses IP.
- Masquer votre adresse IP : Lorsque vous naviguez sur internet ou scrapez un site web, votre adresse IP est exposée. Les sites web peuvent ainsi suivre vos activités en ligne et parfois même vous bloquer. L’utilisation d’un proxy permet de cacher votre véritable adresse IP et d’apparaître sous une autre, offrant ainsi un degré d’anonymat.
- Gérer les restrictions géographiques : Certains sites web limitent leur accès à certaines régions géographiques. Par exemple, les services de streaming ne sont disponibles que dans certains pays. Avec un proxy, vous pouvez « prétendre » être dans cette région en utilisant une adresse IP de cette zone géographique spécifique.
- Amélioration des performances et de la vitesse de navigation : Certains serveurs proxy peuvent mettre en cache (stocker) des pages web. Lorsqu’une requête est faite pour une page web déjà mise en cache, le proxy peut retourner la page web plus rapidement, améliorant ainsi les performances de navigation.
- Bénéficier de la sécurité supplémentaire : En utilisant un proxy, vous pouvez bénéficier d’une sécurité supplémentaire. Les serveurs proxy peuvent fournir des fonctionnalités comme le blocage des sites web malveillants et la protection contre les malwares.
Les types de proxies
Il existe deux types de proxy :
- Proxy HTTP : Le proxy HTTP est conçu spécifiquement pour les requêtes HTTP. Il intercepte les requêtes HTTP et les transmet au serveur web. En retour, il reçoit les réponses du serveur web et les transmet au client. Ce type de proxy est particulièrement idéal pour le web scraping car il est conçu pour interagir avec les sites web de la manière la plus optimale. De plus, le proxy HTTP peut également mettre en cache les pages web pour accélérer les futures requêtes.
- Proxy SOCKS : Contrairement au proxy HTTP, le proxy SOCKS peut gérer tout type de trafic car il opère à un niveau plus bas. Cela signifie qu’il peut gérer non seulement le trafic HTTP, mais aussi le trafic de tout autre protocole. C’est pourquoi il est souvent utilisé pour le partage de fichiers peer-to-peer ou pour les jeux en ligne. Cependant, en raison de sa flexibilité, le proxy SOCKS n’est pas aussi rapide que le proxy HTTP lorsqu’il s’agit de traiter des requêtes HTTP, qui sont le cœur du web scraping. De plus, les proxies SOCKS ne mettent généralement pas en cache les pages web, ce qui peut ralentir les performances de navigation et de scraping.
Comment configurer un proxy pour votre web scraper en Python ?
Utiliser le module requests
Le module requests de Python est une excellente bibliothèque pour effectuer des requêtes HTTP. Heureusement, elle a une fonctionnalité intégrée pour gérer les proxies.
import requests
proxies = {
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.10:1080',
}
requests.get('http://example.org', proxies=proxies)
Remarque : Remplacez ‘10.10.1.10:3128’ et ‘10.10.1.10:1080’ par l’adresse de votre proxy.
Utiliser le module Scrapy
Scrapy est un autre outil Python utile pour le web scraping qui supporte aussi l’utilisation de proxies. Vous pouvez définir le proxy directement dans les paramètres de votre spider Scrapy.
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://example.org']
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url, meta={'proxy': 'http://10.10.1.10:3128'})
Vérifier que le proxy fonctionne avant de scraper un site
import requests
def get_current_ip():
# Cette API renvoie l'adresse IP du client qui fait la requête
url = 'https://api.ipify.org?format=json'
response = requests.get(url)
ip = response.json()['ip']
return ip
def scrape_website(proxy):
# Utilisons l'adresse IP du proxy pour faire une requête sur un site web
url = 'https://httpbin.org/ip'
response = requests.get(url, proxies={"http": proxy, "https": proxy})
return response.json()
# Afficher l'adresse IP actuelle
print("Adresse IP actuelle: ", get_current_ip())
# Définir le proxy - Assurez-vous de remplacer 'your_proxy' par votre adresse de proxy
proxy = {
'http': 'http://user:password@proxyIP:proxyPort',
'https': 'https://user:password@proxyIP:proxyPort'
}
# Scraper le site web en utilisant le proxy
response = scrape_website(proxy)
print("Adresse IP avec le proxy: ", response['origin'])
Dans cet exemple, nous faisons d’abord une requête à l’API ipify pour obtenir notre adresse IP actuelle. Ensuite, nous utilisons notre adresse de proxy pour faire une requête à un site web (httpbin.org). Nous affichons ensuite l’adresse IP retournée par le site web. Si le proxy fonctionne correctement, l’adresse IP retournée par le site web devrait être celle du proxy, et non notre adresse IP actuelle.
Cela dit, n’oubliez pas que tous les sites web ne permettent pas le scraping. Assurez-vous toujours de respecter les politiques d’utilisation des sites web et leurs fichiers robots.txt avant de scraper leurs contenus.
Utiliser l’API de ScrapingBee pour le Web Scraping avec des Proxies
ScrapingBee est une plateforme d’API Web qui permet aux utilisateurs de scraper ou d’extraire des données de n’importe quel site web sans se soucier des problèmes techniques tels que le blocage IP, la gestion des cookies, les requêtes AJAX, les redirections, le CAPTCHA, etc.
C’est un service particulièrement utile pour les développeurs, les data scientists et les entreprises qui ont besoin d’extraire des informations de divers sites web pour l’analyse des données, le machine learning, la veille concurrentielle, etc.
S’inscrire sur ScrapingBee
Rendez vous sur le site officiel ScrapingBee puis cliquez sur « login » en haut à droite. Vous avez avoir la possibilité de vous connecter en quelques secondes grâce à votre compte Google. Une fois connecté à votre tableau de bord vous devriez voir ceci:
Comme vous pouvez le constater, avec la version gratuite, vous allez pouvoir consommer 1000 crédits, ça part assez rapidement en fonction de l’utilisation que l’on fait de l’API. Si vous visez une récolte massive de données, je vous conseille de choisir une de leurs offres. Personnellement, la première m’est souvent suffisante avec ses 150 000 crédits.
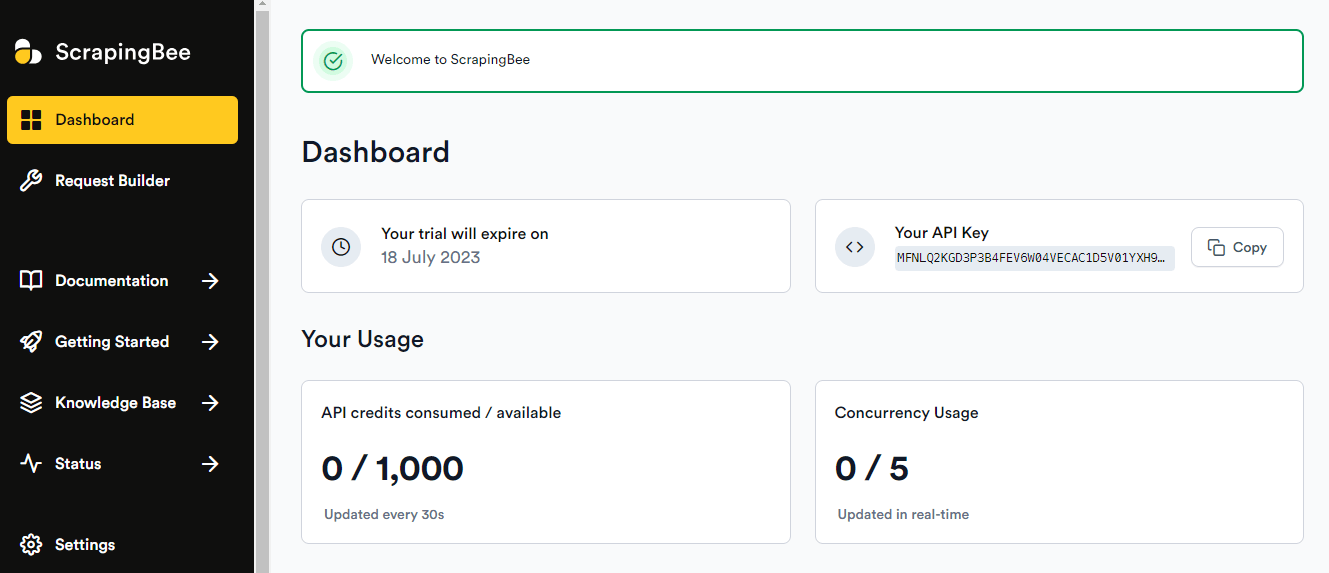
Pensez donc, à bien remplacer « VOTRE_CLE_API » par la clé affichée sur votre tableau de bord ScrapingBee.
Exemple de scraper avec Beautiful Soup
Enfin, nous allons utiliser BeautifulSoup pour analyser la page HTML et extraire des informations sur les produits.
from bs4 import BeautifulSoup
from scrapingbee import ScrapingBeeClient
def scrape_with_bs(url):
scrapingbee = ScrapingBeeClient(api_key='VOTRE_CLE_API')
response = scrapingbee.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
products = soup.select('div.thumbnail')
for product in products:
name = product.select_one('h4 > a').text
price = product.select_one('.price').text
print(f'Product Name: {name} | Price: {price}')
scrape_with_bs('https://webscraper.io/test-sites/e-commerce/allinone/computers')
Si vous avez un faible pour Beautiful Soup, consultez notre article à créer un scraper avec beautiful Soup.
Utilisation des proxies Scrapingbee avec Scrapy
import requests
from scrapy import Selector
def scrape(url):
scrapingbee_url = 'https://app.scrapingbee.com/api/v1'
api_key = 'VOTRE_CLE_API'
response = requests.get(scrapingbee_url, params={'api_key': api_key, 'url': url})
if response.status_code == 200:
selector = Selector(text=response.text)
products = selector.css('div.thumbnail')
for product in products:
name = product.css('h4 > a::text').get()
price = product.css('.price::text').get()
print(f'Product Name: {name} | Price: {price}')
scrape('https://webscraper.io/test-sites/e-commerce/allinone/computers')
Utilisation de la bibliothèque Selenium avec ScrapingBee
Dans cet exemple, nous utiliserons les capacités du navigateur pour définir les paramètres du proxy et charger la page via le proxy ScrapingBee. Pensez à télécharger une version à jour du chromedriver.
from selenium import webdriver
from selenium.webdriver.common.proxy import Proxy, ProxyType
def scrape_with_selenium(url):
proxy_url = "http://app.scrapingbee.com/api/v1?api_key=VOTRE_CLE_API&url=" + url
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server=%s' % proxy_url)
driver = webdriver.Chrome(options=chrome_options)
driver.get(url)
titles = driver.find_elements('css selector','h4 > a')
prices = driver.find_elements('css selector','.price')
for title, price in zip(titles, prices):
print(f'Product Name: {title.text} | Price: {price.text}')
driver.quit()
scrape_with_selenium('https://webscraper.io/test-sites/e-commerce/allinone/computers')
Mettre en place un système de rotation de proxy
import requests
from itertools import cycle
proxies = [
'proxy1',
'proxy2',
'proxy3',
'proxy4',
# Ajoutez autant de proxies que vous en avez
]
proxy_pool = cycle(proxies) # Crée un cycle de proxies
url = "https://webscraper.io/test-sites/e-commerce/allinone/computers"
for i in range(1, 11): # Faire 10 requêtes
proxy = next(proxy_pool) # Obtenir le proxy suivant dans le cycle
print(f"Request #{i}: Proxie utilisé {proxy}")
try:
response = requests.get(url, proxies={"http": proxy, "https": proxy})
print(response.text)
except:
print("Skipped. Connexion error")
Dans cet exemple, nous avons une liste de proxies et nous utilisons la fonction cycle de la bibliothèque itertools pour créer un cycle de proxies. Pour chaque requête, nous utilisons le proxy suivant dans le cycle.
Remarque : Vous devez remplacer 'proxy1', 'proxy2', etc., par vos propres adresses de proxy. Ce sont juste des placeholders.
Liste de proxy gratuits à utiliser pour votre scraper
Il existe plusieurs sites de proxy gratuits sur Internet. Cependant, comme ils sont gratuits, ils peuvent être facilement surchargés par un grand nombre d’utilisateurs et donc être plus lents. De plus, de nombreux sites, dont Google, peuvent détecter ces proxies gratuits et déclencher des CAPTCHA ou même bloquer les requêtes. Voici quelques sites de proxy gratuits :
- Free Proxy CZ (http://free-proxy.cz/en/)
- Free Proxy List (https://free-proxy-list.net/)
- ProxyScrape (https://www.proxyscrape.com/free-proxy-list)
Comment contourner le CAPTCHA Google avec son Scraper
Contourner les CAPTCHA lors du scraping d’un site web est une tâche plutôt rude ! Il est important de noter que l’évitement des CAPTCHA peut être considéré comme une activité suspecte par de nombreux sites web et peut entraîner l’interdiction de votre adresse IP, voire une violation des termes de service du site. Cela dit, il existe plusieurs techniques pour contourner les CAPTCHA, chacune avec ses propres avantages et inconvénients.
- Utilisation de services de résolution de CAPTCHA: Des services tels que 2Captcha, DeathByCaptcha et Anti-Captcha emploient des humains pour résoudre les CAPTCHAs pour vous. Vous envoyez l’image du CAPTCHA à ces services via leur API, ils la résolvent et vous renvoient la réponse que vous pouvez entrer sur le site web. Bien que ces services soient généralement fiables, ils ne sont pas gratuits et peuvent ralentir votre programme de scraping.
- Utilisation de bibliothèques OCR (Optical Character Recognition): Certaines bibliothèques Python comme Tesseract peuvent être utilisées pour reconnaître les caractères dans les CAPTCHAs basés sur du texte. Cependant, cette approche est généralement moins efficace car de nombreux CAPTCHAs modernes sont conçus pour résister à l’OCR.
- Utilisation de l’IA et du Machine Learning: Des approches plus sophistiquées pour résoudre les CAPTCHAs peuvent impliquer l’utilisation de l’intelligence artificielle et de l’apprentissage automatique pour « apprendre » à résoudre les CAPTCHAs basés sur des exemples antérieurs. Ces techniques peuvent être très efficaces, mais elles nécessitent une grande quantité de données et de compétences techniques pour être mises en œuvre.
- Évitement de CAPTCHA: Plutôt que de tenter de résoudre les CAPTCHAs, une autre approche consiste à essayer de les éviter complètement. Cela peut impliquer des techniques comme le scraping à faible volume, la rotation des adresses IP et l’imitation du comportement humain (comme l’introduction de délais entre les requêtes) pour essayer de rester sous le radar du site web et d’éviter de déclencher le CAPTCHA en premier lieu.
Le bon conseil
Pensez à votre web scraper comme un invité poli qui respecte les règles de la maison (le site web). Trop d’invitations non sollicitées (demandes) pourraient faire de vous un invité non désiré (être bloqué).
Alors, faites preuve de courtoisie et n’oubliez pas d’utiliser un proxy!
Rappelez-vous que l’art du web scraping n’est pas seulement une question de codage, mais aussi de savoir jongler avec les outils disponibles comme les proxies pour rendre votre tâche plus efficace et plus respectueuse des sites web que vous scrappez. Alors, restez curieux, continuez à expérimenter et à vous amuser en codant !


